AI & ChatGPT searches , social queriess for RUNIC UNICODE-BLOCK
Search references for RUNIC UNICODE-BLOCK. Phrases containing RUNIC UNICODE-BLOCK
See searches and references containing RUNIC UNICODE-BLOCK!Search references for RUNIC UNICODE-BLOCK. Phrases containing RUNIC UNICODE-BLOCK
See searches and references containing RUNIC UNICODE-BLOCK!RUNIC UNICODE-BLOCK
Unicode character block
Runic is a Unicode block containing runic characters. It was introduced in Unicode 3.0 (1999), with eight additional characters introduced in Unicode

Runic_(Unicode_block)
Uyghur (Unicode block) Palmyrene (Unicode block) Phaistos Disc (Unicode block) Phoenician (Unicode block) Psalter Pahlavi (Unicode block) Runic (Unicode block)
![]()
List_of_Unicode_characters
Named range of Unicode code points
A Unicode block is one of several contiguous ranges of numeric character codes (code points) of the Unicode character set that are defined by the Unicode
Unicode_block
Ancient Germanic letters
after which they are named (ideographic runes). Runology is the academic study of the runic alphabets, runic inscriptions, runestones, and their history

Runes
Late runic script
progressively replace the runes. At the end of the 16th century, the Dalecarlian runic inventory was almost exclusively runic, but during the following

Dalecarlian_runes
Artificial script in Tolkien's writings
⟨sh⟩ graphemes, as follows: U+16F1 ᛱ RUNIC LETTER K U+16F2 ᛲ RUNIC LETTER SH U+16F3 ᛳ RUNIC LETTER OO A formal Unicode proposal to encode Cirth as a separate

Cirth
Purposely unassigned Unicode code points
In Unicode, a Private Use Area (PUA) is a range of code points that, by definition, will not be assigned characters by the standard. Three Private Use
Private_Use_Areas
Twelfth letter of the Latin alphabet
Latin L ᛚ : Runic letter laguz, which might derive from old Italic L 𐌻 : Gothic letter laaz The Latin letters ⟨L⟩ and ⟨l⟩ have Unicode encodings U+004C

L
Alphabet used for writing the Gothic language
to be East Germanic, possibly Gothic (see Gothic runic inscriptions). The influence of Latin and Runic letters on the Gothic alphabet is disputed, and

Gothic_alphabet
Project coordinating the encoding of medieval texts using the Private Use Area
medieval texts written in the Latin alphabet or in runes, which are not otherwise encoded as part of Unicode. MUFI was founded in July 2001 by a workgroup
Medieval Unicode Font Initiative

Medieval_Unicode_Font_Initiative
Continuous group of 65536 Unicode code points
plane have been allocated to a Unicode block, leaving 16 code points in a single unallocated range (2FE0..2FEF). As of Unicode 17.0[update], the BMP comprises
Plane_(Unicode)
Letter of written Old Norse
April 2008 as part of the Latin Extended-D block of Unicode 5.1 "Unicode Utilities: Character Properties". util.unicode.org. Retrieved 2022-11-03. v t e
Vend_(letter)
Character encoding standard
uncommon Unicode characters. Without proper rendering support, you may see question marks, boxes, or other symbols. Unicode (also known as The Unicode Standard
![]()
Unicode
Alphabetic writing system used by the Hungarians primarily in the Middle Ages
és rovásírás (Runes and runic writing, Budapest, 1909) and A magyar rovásírás hiteles emlékei (The authentic relics of Hungarian runic writing, Budapest

Old_Hungarian_script
Script used to write the Greek language
ᾱ́. There are two main blocks of Greek characters in Unicode. The first is "Greek and Coptic" (U+0370 to U+03FF). This block is based on ISO 8859-7 and
Greek_alphabet
Letter in several Latin-script alphabets
a diacritical variant of the letter ⟨o⟩, it is informally known as the "Runic O" or "Nordic O", it is considered a separate letter in Danish and Norwegian

Ø
Unicode character block
a Unicode block containing characters for representing Primitive Irish language inscriptions as codified in the Ogham script. The following Unicode-related
Ogham_(Unicode_block)
Alphabet used by early Turks (8-10th centuries)
𐰞𐱃𐰢: 𐰚𐰃: 𐰠𐱅𐰋𐰼𐰠𐰏: 𐰉𐰆𐰑𐰣: The Unicode block for Old Turkic is U+10C00–U+10C4F. It was added to the Unicode standard in October 2009, with the release
Old_Turkic_script
Family of writing systems in ancient Italy
Linear B Old European script Trojan script Old Italic (PDF) (chart), Unicode. "runic alphabet | writing system". Encyclopædia Britannica. 2 September 2022
Old_Italic_scripts
Unicode character block
Old Hungarian is a Unicode block containing characters used for writing the Old Hungarian alphabet, an obsolete script which was used to write Hungarian
Old_Hungarian_(Unicode_block)
Unicode serif typeface
Medieval Unicode Font Initiative, and it includes 10,044 glyphs (9,341 characters) in version 3.0 (2000) (revision 4.0) from the following Unicode blocks: Basic

Bitstream_Cyberbit
Modern use of runic alphabets
recognition with the introduction of three extra runes to the Unicode Runic block used by him in Unicode version 7.0 (2014). The three characters represent
Modern_runic_writing
Typographical symbol
are two Unicode characters dedicated for this: U+16EB ᛫ RUNIC SINGLE PUNCTUATION U+16EC ᛬ RUNIC MULTIPLE PUNCTUATION Up to the mid twentieth century, and
Interpunct
Unicode code point property names and their uses
The Unicode Standard assigns various properties to each Unicode character and code point. The properties can be used to handle characters (code points)
Unicode_character_property
Computer font that maps glyphs to code points defined in the Unicode Standard
Unicode font is a computer font that maps glyphs to code points defined in the Unicode Standard. The term has become archaic because the vast majority
Unicode_font
Glyph combining two or more letterforms
rather than as a ligature: ຫລ (l). In many runic texts ligatures are common. Such ligatures are known as bind-runes and were optional. Written Chinese has

Ligature_(writing)
Framework. "Bamum (Unicode block)" (PDF). Unicode Character Code Charts. Unicode Consortium. "Mende Kikakui (Unicode block)" (PDF). Unicode Character Code
List_of_numeral_systems
North Germanic language
separately in Unicode as of this section's writing. Old East Norse or Old East Nordic between 800 and 1100 is called Runic Swedish in Sweden and Runic Danish

Old_Norse
Unicameral alphabet
alphabet. Wancho script was added to the Unicode Standard in March 2019 on version 12.0. The Unicode block for Wancho is U+1E2C0–U+1E2FF: Everson, Michael

Wancho_script
Unicode character block
Supplemental Punctuation is a Unicode block containing historic and specialized punctuation characters, including biblical editorial symbols, ancient

Supplemental_Punctuation
Early Medieval Irish alphabet
similar runic alphabet based on the Celtic vigesimal system invented by Iolo Morganwg for the Welsh language. Ogham inscription Primitive Irish Runic alphabet

Ogham
Font family
includes 4,178 glyphs. The family covers characters from the following Unicode blocks: Basic Latin Latin-1 Supplement Latin Extended-A Latin Extended-B International

GNU_FreeFont
Subset of characters in Unicode
v t e In Unicode, a script is a collection of letters and other written signs used to represent textual information in one or more writing systems. Some
Script_(Unicode)
Semisyllabary used to transcribe Chinese
8+I+K+,) Bopomofo was added to the Unicode Standard in October 1991 with the release of version 1.0. The Unicode block for Bopomofo is U+3100–U+312F: Additional
Bopomofo
Relationship between Unicode characters and HTML
multilingual text represented with the Unicode universal character set. Key to the relationship between Unicode and HTML is the relationship between the
Unicode_and_HTML
Typeface
Code2000 is a serif and pan-Unicode digital font, which includes characters and symbols from a very large range of writing systems. As of the current

Code2000
Historic Aramaic-based alphabet
Uyghur alphabet was added to the Unicode Standard in September, 2021 with the release of version 14.0. The Unicode block for Old Uyghur is U+10F70–U+10FAF:
Old_Uyghur_script
Script used for writing the Coptic language
Numerical Use of Letters" (PDF). The Unicode Standard. The Unicode Consortium. July 2016. "Revision of the Coptic block under ballot for the BMP of the UCS"
Coptic_script
Variations on the religious symbol through Christian history
documents made using a computer, there are Unicode code-points for multiple types of Christian crosses. U+16ED ᛭ RUNIC CROSS PUNCTUATION U+205C ⁜ DOTTED CROSS

Christian_cross_variants
Systems for transcribing the Old Norse language
orthography of the Old Norse language was diverse, being written in both Runic and Latin alphabets, with many spelling conventions, variant letterforms

Old_Norse_orthography
Writing system
Puachue Hmong script was added to the Unicode Standard on March 5, 2019 with the release of version 12.0. The Unicode block for Nyiakeng Puachue Hmong is U+1E100–U+1E14F:
Nyiakeng_Puachue_Hmong
American-Irish type designer (born 1963)
Umamaheswaran) of the Unicode roadmaps that detail actual and proposed allocations for current and future Unicode scripts and blocks. On July 1, 2012, Everson

Michael_Everson
There are Unicode typefaces which are open-source and designed to contain glyphs of all Unicode characters, or at least a broad selection of Unicode scripts

Open-source_Unicode_typefaces
Alphabet of the Arabic language
forms can also be encoded separately. As of Unicode 17.0, the Arabic script is contained in the following blocks: Arabic (0600–06FF, 256 characters) Arabic

Arabic_alphabet
Historic European script and typeface
term today more often refers to typefaces, for example the Fraktur unicode block. Black letter was used as a descriptive term to distinguish the heavy

Blackletter
Monospace Unicode font
Everson Mono is a monospaced humanist sans serif Unicode font whose development by Michael Everson began in 1995. Its signature feature is that it is

Everson_Mono
Cuneiform consonantal alphabet of 30 letters
Ugaritic script was added to the Unicode Standard in April, 2003 with the release of version 4.0. The Unicode block for Ugaritic is U+10380–U+1039F: Six

Ugaritic_alphabet
Script for Old South Arabian languages
Arabian alphabet was added to the Unicode Standard in October, 2009 with the release of version 5.2. The Unicode block, called Old South Arabian, is U+10A60–U+10A7F

Ancient_South_Arabian_script
Script of various Middle Iranian languages
Unicode. The Unicode block for Inscriptional Pahlavi is U+10B60–U+10B7F: The Unicode block for Inscriptional Parthian is U+10B40–U+10B5F: The Unicode
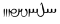
Pahlavi_scripts
Family of programming languages
operators /\ and \/. 1962: ALCOR – This character set included the unusual "᛭" runic cross character for multiplication and the "⏨" Decimal Exponent Symbol for

ALGOL
Alphabet used to write the Lydian language
the Unicode Standard in April, 2008 with the release of version 5.1. It is encoded in Plane 1 (Supplementary Multilingual Plane). The Unicode block for

Lydian_alphabet
Multilingual font family from Google
ideographs defined in Unicode version 6.0 were covered by Noto fonts. None of the 53 scripts and 1 block encoded between Unicode versions 6.1 and 11.0

Noto_fonts
Historical Middle Eastern alphabet
inscriptions. Palmyrene was added to the Unicode Standard in June, 2014 with the release of version 7.0. The Unicode block for Palmyrene is U+10860–U+1087F:

Palmyrene_alphabet
Two alphasyllabaric scripts for the extinct Meroitic language
Unicode Standard in January, 2012 with the release of version 6.1. The Unicode block for Meroitic Hieroglyphs is U+10980–U+1099F. The Unicode block for

Meroitic_script
Writing system
released in Unicode 5.0 and earlier, the names will either be blank (Microsoft Word applications) or "Undefined" (Character Map). The Unicode block for Vai
Vai_syllabary
Character as a semiotic sign or symbol
especially for foreign or mysterious graphemes (such as Chinese, Syriac, or Runic ones) as opposed to the familiar letters; in particular of shorthand (in
Character_(symbol)
Text that contains both LTR and RTL text
directional formatting characters are the classical Unicode method of explicit formatting, and as of Unicode 6.3, are being discouraged in favor of "isolates"
Bidirectional_text
Typographical mark (`) (Freestanding grave accent)
prime. This had a number of problems that led most modern systems and Unicode to render the apostrophe as a "straight" one: Open quote is not typographically
Backtick
Writing system used by the Samaritans for religious writings
Samaritan script was added to the Unicode Standard in October 2009 with the release of version 5.2. The Unicode block for Samaritan is U+0800–U+083F: Samaritan

Samaritan_script
Script used to write the Aramaic language
Aramaic alphabet was added to the Unicode Standard in October 2009, with the release of version 5.2. The Unicode block for Imperial Aramaic is U+10840–U+1085F:

Aramaic_alphabet
Geometrical figure
ten). Unicode has a variety of cross symbols in the "Dingbat" block (U+2700–U+27BF): ✕ ✖ ✗ ✘ ✙ ✚ ✛ ✜ ✝ ✞ ✟ ✠ ✢ ✣ ✤ ✥ The Miscellaneous Symbols block (U+2626

Cross
Monospaced typeface family
297 glyphs in Bold weight, version 0.830 (2023) from the following Unicode blocks: PragmataPro sample text in Windows at 12 pt anti aliased PragmataPro

PragmataPro
Writing system
[citation needed] Unicode 5.1, released on 4 April 2008, introduces major changes to the Cyrillic blocks. Revisions to the existing Cyrillic blocks, and the addition

Cyrillic_script
Alphabet used to write the Armenian language
the Unicode Standard and assigned a code for the sign – U+058F (֏). In 2012 the sign was finally adopted in the Armenian block of ISO and Unicode international

Armenian_alphabet
Tibetan writing system
originally one of the scripts in the first version of the Unicode Standard in 1991, in the Unicode block U+1000–U+104F. However, in 1993, in version 1.1, it

Tibetan_script
Abugida script for the Khmer language
the Khmer subscripting character (see under Unicode). "Character Code Chart for the Khmer Unicode block" (PDF). Jacob, Judith M. (1968). Introduction
Khmer_script
19th-century phonetic writing system devised by the LDS Church
University of Utah: Utah Digital Newspapers. "The Unicode Standard, version 4.0: UnicodeData-4.0.0.txt". The Unicode Consortium. Retrieved 25 January 2017. "ALA-LC
Deseret_alphabet
Script used for languages in Ethiopia and Eritrea
(multiple weights and widths). Covers blocks through Extended-A. Chart correlating IPA values for the Amharic alphabet Unicode specification Ethiopic Ethiopic

Geʽez_script
Quadrilateral with sides of equal length
up, down, left and right, is defined in the Miscellaneous Technical Unicode block as U+2311 ⌑ SQUARE LOZENGE. It is used in travel agencies, where it
Lozenge_(shape)
Typeface family commonly used by Microsoft
previously, Ogham and Runic glyphs. It is not, however, a "symbol charset-encoded font" (like MS Symbol), but rather it is a Unicode-encoded font with symbols
Segoe
Writing system
Abbreviation Mark (U+070F). The Unicode block for Suriyani Malayalam specific letters is called the Syriac Supplement block and is U+0860–U+086F: Note: HTML
Syriac_alphabet
Oldest known Slavic alphabet
Glagolitic alphabet was added to the Unicode Standard in March 2005 with the release of version 4.1. The Unicode block for Glagolitic is U+2C00–U+2C5F. The

Glagolitic_script
Uppercase or lowercase
"Character Properties, Case Mappings & Names FAQ". Unicode. Retrieved 19 February 2017. "Unicode Technical Note #26: On the Encoding of Latin, Greek

Letter_case
Alphabet of the Hebrew language
occasionally, a gimel function is used in cardinal notation. The Unicode Hebrew block extends from U+0590 to U+05FF and from U+FB1D to U+FB4F. It includes
Hebrew_alphabet
Ancient script of Central and South Asia
You may need rendering support to display the uncommon Unicode characters in this article correctly. Kharosthi script (Gāndhārī: 𐨑𐨪𐨆𐨮𐨿𐨛𐨁𐨌 𐨫𐨁𐨤𐨁

Kharosthi
Alphabet used by the Etruscans of central and northern Italy
depending on the locality. Shown above are the glyphs from the Unicode Old Italic block, whose appearance will depend on the font used by the browser.

Etruscan_alphabet
Writing found in Canaanite inscriptions
highland (Hebrew) association (cf. the Zayit Stone abecedary). The Unicode block Phoenician (U+10900–U+1091F) is intended for the representation of,
Paleo-Hebrew_alphabet
Character in alphabet writing systems
ISBN 978-0-7679-1172-6. OCLC 51210302. Wikimedia Commons has media related to Letters. Look up letter in Wiktionary, the free dictionary. Unicode Code Charts
Letter_(alphabet)
Punctuation mark (;)
U+204F ⁏ REVERSED SEMICOLON – used in old writing systems, such as Hungarian Runic and Sindhi language U+236E ⍮ APL FUNCTIONAL SYMBOL SEMICOLON UNDERBAR –
Semicolon
Abugida script for languages spoken in Thailand
script. Thai script was added to the Unicode Standard in October 1991 with the release of version 1.0. The Unicode block for Thai is U+0E00–U+0E7F. It is
Thai_script
Script used to censor words or phrases on the internet
Moderation Services. Online Text Obfuscator – replaces characters with similar Unicode chars from different character sets (e.g. Cyrillic) Text Filter – Text
Wordfilter
rates among them. alphabet originally created to this language replaced the runic alphabet replaced the Ogham replaced the Arabic alphabet replaced the Arabic

List_of_writing_systems
Writing systems for indigenous North American languages
consonant), and the Unicode Consortium considers syllabics to be a "featural syllabary" along with such scripts as hangul, where each block represents a syllable

Canadian_Aboriginal_syllabics
Set of letters used to write a given language
(1980). Runes, an introduction. Manchester University Press. ISBN 0-7190-0787-9. "Proposal for Arabic Mathematical Alphabetic Symbols" (PDF). Unicode Consortium

Alphabet
Ancient Eurasian icon and Nazi symbol
"卍字" (manji). The swastika is included in the Unicode character sets of two languages. In the Chinese block, it is U+534D 卍 (left-facing) and U+5350 for

Swastika
Latest stage of the Egyptian language
comprehensive Coptic language resource (Remenkimi) (Internet Archive) Coptic block in the Unicode 4.1 standard Heike Behlmer, Selected Bibliography on the Coptic Language

Coptic_language
ongoing development. Constructed script List of writing systems ConScript Unicode Registry "Echo Station - Aurebesh Soup". 19 April 2016. Archived from the
List_of_constructed_scripts
Chess notation algebraic descriptive PGN annotation symbols symbols in Unicode Fianchetto Gambit Key square King walk Open file Half-open file Outpost
List_of_chess_grandmasters
Writing system used for the Sudanese language
Northern Coast Bekasi Bogor Depok Related topics Numerals Rinéka sora Sundanese literature Sundanese Language Congress Wikipedia Unicode block Supplement

Old_Sundanese_script
or other symbols instead of Unicode combining characters and Latin characters. This article contains uncommon Unicode characters. Without proper rendering
Glossary of sound laws in the Indo-European languages

Glossary_of_sound_laws_in_the_Indo-European_languages
It returns None in the cases in which indexing would panic. Ruby lacks Unicode support See the str::len method. In Rust, the str::chars method iterates
Comparison of programming languages (string functions)
Comparison_of_programming_languages_(string_functions)
support, you may see question marks, boxes, or other symbols instead of Unicode combining characters and Latin characters. Proto-Indo-European mythology

Proto-Indo-European_mythology
Archaic script used in Java and Bali
Northern Coast Bekasi Bogor Depok Related topics Numerals Rinéka sora Sundanese literature Sundanese Language Congress Wikipedia Unicode block Supplement
Buda_script
Extinct language of ancient Italy
applet and a summary of Etruscan grammar. Etruscan font download site with unicode information Etruscan and Early Italic Fonts by James F. Patterson

Etruscan_language
Official language of Mongolia
stages of Mongolian (Xianbei, Wuhuan languages) may have used an indigenous runic script as indicated by Chinese sources. The Khitan large script adopted

Mongolian_language
Ancient Indo-Aryan language of South Asia, mainly Indian subcontinent
speed of entry as well as rendering issues. With the wide availability of Unicode-aware web browsers, IAST has become common online. It is also possible

Sanskrit
Indo-European language
identified dialects. Armenian can be divided into two major dialectal blocks and those blocks into individual dialects, though many of the Western Armenian dialects

Armenian_language
RUNIC UNICODE-BLOCK
RUNIC UNICODE-BLOCK
Girl/Female
Hindu, Indian
Unicorn
Boy/Male
Indian, Punjabi, Sikh
A Quiet Unicorn Bounces All Lollipops
Girl/Female
English
Abbreviation of Nicole, meaning victory.
Girl/Female
Christian & English(British/American/Australian)
People's Victory
Male
Chinese
second brother unicorn.
Boy/Male
American, Australian, French, Greek, Swedish
Victory of the People
Female
English
Pet form of French Nicole, NICOLETTE means "victor of the people."
Girl/Female
English American
Abbreviation of Nicole, meaning victory.
Girl/Female
American, Australian, British, Danish, English, French, Greek
Victory of the People; Abbreviation of Nicole; Victory
Male
Danish
, a wild boar.
Female
English
English variant spelling of Latin Eunice, UNICE means "good victory."
Girl/Female
Australian, Christian, Greek
Victorious; Good Victory
Female
English
Feminine form of French Nicolas, NICOLE means "victor of the people."
Girl/Female
English
Abbreviation of Nicole, meaning victory.
Girl/Female
Australian, Greek, Slavic
Slavic Form of Nicole
Boy/Male
Hindu
Young girl
Girl/Female
Greek American
People's victory.
Girl/Female
American, Australian, British, Chinese, Danish, Dutch, English, French, German, Greek, Jamaican, Lebanese, Portuguese, Swiss
Victory of the People; Female Version of Nicholas; People of Victory
Girl/Female
English American Greek Japanese
Abbreviation of Nicole, meaning victory.
Female
English
English name derived from the Old Saxon runic letter jera, JERA means "year."
RUNIC UNICODE-BLOCK
RUNIC UNICODE-BLOCK
Boy/Male
Arabic, Muslim, Sindhi
Intelligent
Boy/Male
Latin Hungarian
Free.
Boy/Male
Indian
Wish
Male
Dutch
, of Mars.
Girl/Female
Assamese, Gujarati, Hindu, Indian, Kannada, Malayalam, Marathi, Sindhi, Tamil, Telugu
Lotus; Goddess Lakshmi; Born from Water
Biblical
hanging up; heaping up
Boy/Male
Biblical
My Lord is most high; Lord of might and elevation.
Boy/Male
Tamil
Royal salute
Girl/Female
Tamil
Wealthy
Boy/Male
American, Armenian, British, Christian, Czechoslovakian, Danish, Dutch, English, French, German, Greek, Hawaiian, Hebrew, Hindu, Indian, Irish, Italian, Jamaican, Lebanese, Portuguese, Swedish, Swiss
Listening Intently; He who has Heard; The Word of God; To Hear or be Heard
RUNIC UNICODE-BLOCK
RUNIC UNICODE-BLOCK
RUNIC UNICODE-BLOCK
RUNIC UNICODE-BLOCK
RUNIC UNICODE-BLOCK
n.
An under-garment worn by the ancient Romans of both sexes. It was made with or without sleeves, reached to or below the knees, and was confined at the waist by a girdle.
n.
A salt of rutic acid.
n.
See Mantle, n., 3 (a).
a.
Funicular.
a.
Of or pertaining to the ancient Carthaginians.
n.
The kamichi; -- called also unicorn bird.
a.
Characteristic of the ancient Carthaginians; faithless; treacherous; as, Punic faith.
n.
Same as Tunicle.
n.
A chiton, or loose, ungirded tunic, falling in straight folds.
a.
Having a tunic, or mantle; of or pertaining to the Tunicata.
a.
Of a red color; reddish; as, the erythroid tunic (the cremaster muscle).
a.
Covered with a tunic; covered or coated with layers; as, a tunicated bulb.
n.
An ancient manner of writing; ancient writings, collectively; as, Punic paleography.
a.
Pertaining to, or obtained from, rue (Ruta); as, rutic acid, now commonly called capric acid.
n.
The larva of a unicorn moth.
a.
Of or pertaining to a rune, to runes, or to the Norsemen; as, runic verses; runic letters; runic names; runic rhyme.
n.
The Unicorn, a constellation situated to the east Orion.
n.
Any similar garment worm by ancient or Oriental peoples; also, a common name for various styles of loose-fitting under-garments and over-garments worn in modern times by Europeans and others.
n.
A membrane, or layer of tissue, especially when enveloping an organ or part, as the eye.
n.
A natural covering; an integument; as, the tunic of a seed.